[2부] 06장 문자열 조작
3부 (선형 자료구조), 4부 (비선형 자료구조)에 들어가기 전에
2부 (파이썬) 마지막에 06장 문자열 조작으로 구성되어 있음.
문자열 조작 (String Manipulation) 이란?
- 문자열을 변경하거나 분리하는 등의 여러 과정.
- 문자열 처리와 관련한 알고리즘이 쓰이는 대표적인 분야
- 정보 처리 분야 (e.g. 어떤 키워드로 웹 페이지를 탐색할 때)
- 통신 시스템 분야 (e.g. 문자 메시지나 이메일을 보낼 때)
- 프로그래밍 시스템 분야 (e.g. 프로그램은 그 자체가 문자열로 구성되어 있음)
문자열 조작 part 에서 다루는 문제
| no. | title | leetcode | status |
| 1 | 유효한 팰린드롬 | 리트코드 125 | O |
| 2 | 문자열 뒤집기 | 리트코드 344 | O |
| 3 | 로그 파이 재정렬 | 리트코드 937 | X (문제 이해 못함) |
| 4 | 가장 흔한 단어 | 리트코드 819 | O |
| 5 | 그룹 애너그램 | 리트코드 49 | O |
| 6 | 가장 긴 팰린드롬 부분 문자열 | 리트코드 5 | X (시도 중) |
No.01 유효한 팰린드롬
팰린드론: 앞뒤가 똑같은 단어와 문장.

My Solution 1) 접근 방식

reverse() & reversed()
- reverse(): return 값 없고, 리스트에 있는 값의 순서를 거꾸로 뒤집음.
- reversed(): 순서가 거꾸로 뒤집힌 리스트를 반환함. => 정확하게는 '이터레이터' 형식의 값을 리턴.
- 이를 다시 리스트로 형변환하기 위해서 list() 함수 사용해야 함.

list는 mutable 한 객체이기 때문에, 예상과는 다른 값이 나옴.
strs 리스트 로 접근.

My Solution 2)


책 풀이
- Data cleansing (입력값에 대한 전처리)
- isalnum()
- 정규식
- 리스트 뒤집기
- pop() (일반 리스트, deque)
- 슬라이싱
Solution 1) isalnum() & pop() (일반 리스트)


Solution 2) isalnum() & pop() (deque)
- Deque = Double ended Queue (10장 데크, 우선순위 큐)
- 큐는 FIFO 이므로, 삽입하는 부분과 추출하는 부분이 다름.
- 데크는 삽입한 부분에서 꺼낼수도 있고, 꺼내는 부분에 삽입할 수도 있음.
- 양방향으로 삽입/삭제가 가능한 자료형으로, Queue 보다 유연하게 사용될 수 있는 자료형.
- 리스트의 pop(0)이 O(n), 데크의 popleft()는 O(1)이기 때문에 성능 차이가 큼.



Solution 3) 정규식 & 슬라이싱


No.02 문자열 뒤집기

My solution)
- reverse() 함수 사용


책 풀이
Solution 1) 투 포인터를 이용한 스왑


Solution 2) Pythonic way (reverse())

No.03 로그 파일 재정렬
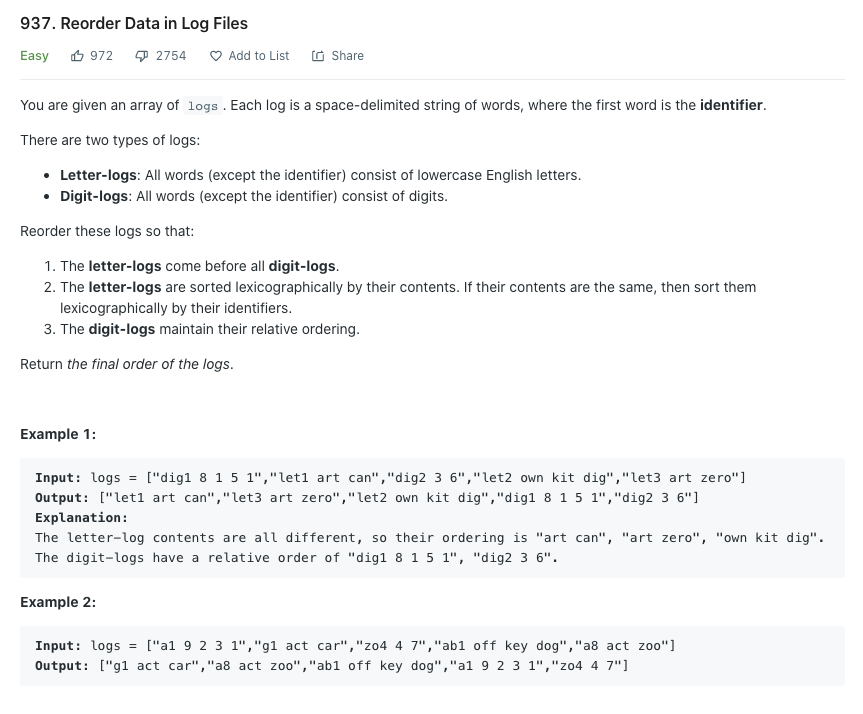
pass
No.04 가장 흔한 단어

My solution)


책 풀이
Solution 1) 리스트 컴프리헨션, Counter 객체


No.05 그룹 애너그램
애너그램: 문자를 재배열하여 다른 뜻을 가진 단어로 바꾸는 것

My solution)



책 풀이
Solution 1) 정렬하여 딕셔너리에 추가

1. sorted()와 join() 함수를 한 줄로 해결함.
2. anagram_dict에서 value 값을 한번에 추출함.

여러 가지 정렬 방법
sorted() 함수
- 리스트, 숫자, 문자 정렬 가능.
b = 'bcsa'
sorted(b) # 결과값 ['a,'b','c','s']
b = "".join(b) #join() 함수로 다시 문자열로 결합.
# 다음과 같이 한 번에 사용할 수 있음.
b = "".join(sorted(b))
- key = 옵션을 지정해, 정렬을 위한 키, 함수를 별도로 지정할 수 있음.
c = ['aaaa', 'bbb', 'cc', 'd']
# 1. 길이(len)를 키 값으로 지정해 정렬
sorted(c, key=len) #결과값 ['d', 'cc', 'bbb', 'aaaa']
# 2-1. 함수를 이용해 키 정의
a = ['cde', 'cfc', 'abc']
def fn(s):
return s[0], s[-1]
print(sorted(a, key=fn)) #결과값 ['abc', 'cfc', 'cde'],
# 2-2. 람다 함수를 이용해 한 줄로 처리
sorte(a, key=lamdba s: (s[0], s[-1]))
No.06 가장 긴 팰린드롬 부분 문자열

pass
re 정규식
메타 문자 12개: 각각의 문자 하나에 매칭되지 않음.
(e.g. 일반 문자인 a 는 'a'에 매칭되지만, ( 는 문자 ' ( '와 매칭되지 않음.)
$ ( ) * + . ? [ \ ^ { |
찾고자 하는 문자열에 메타 문자가 있다면?
메타 문자 앞에 백슬래시 \ 를 붙여 주면 일반 문자처럼 한 글자에 매칭됨.
re 패키지 기본 method
인자로 1) pattern, 2) string, 3) flags를 받음. 각각 인자는 1) 패턴, 2) 패턴을 찾을 문자열 3) 옵션을 의미함. 3) 옵션은 필수는 아님.
re.match(pattern, string, flags)
re.match 함수: '문자열의 처음'부터 시작하여 패턴이 일치되는 것이 있는지 확인.
CODE
matchObj = re.match('a', 'a')
print(matchObj)
print(re.match('a', 'aba'))
print(re.match('a', 'baa'))OUTPUT
<_sre.SRE_Match object; span=(0, 1), match='a'>
<_sre.SRE_Match object; span=(0, 1), match='a'>
None
re.search(pattern, string, flags)
re.search 함수: re.match 함수와 비슷하지만, '반드시 처음부터 일치해야 하는 것은 아님'.
CODE
matchObj = re.search('a', 'a')
print(matchObj)
print(re.search('a', 'aba'))
print(re.search('a', 'baa'))OUTPUT
<_sre.SRE_Match object; span=(0, 1), match='a'>
<_sre.SRE_Match object; span=(0, 1), match='a'>
<_sre.SRE_Match object; span=(1, 2), match='a'>
re.findall(pattern, string, flags)
re.findall 함수: 문자열 중 패턴과 일치되는 모든 부분을 찾음.
CODE
matchObj = re.findall('a', 'a')
print(matchObj)
print(re.findall('a', 'aba'))
print(re.findall('a', 'baa'))OUTPUT
['a']
['a', 'a']
['a', 'a']
re.fullmatch(pattern, string, flags)
re.fullmatch 함수: 패턴과 문자열이 남는 부분 없이 완벽하게 일치하는지 검사.
CODE
matchObj = re.fullmatch('a', 'a')
print(matchObj)
print(re.fullmatch('a', 'aba'))
print(re.fullmatch('a', 'baa'))OUTPUT
<_sre.SRE_Match object; span=(0, 1), match='a'>
None
None
re.sub(pattern, repl, string, count, flags)
re.sub 함수: 패턴에 일치되는 문자열를 다른 문자열로 바꿔줌.
CODE
print(re.sub(pattern = 'c+', relp = 'a+', count = 2, string = 'a+ a+ b+ c+ c+ c+ p'))OUTPUT
a+ a+ b+ a+ a+ c+ p[ ] 대괄호: 여러 문자 중 하나와 일치
대괄호 [ 와 ] 사이에 원하는 문자를 여러 개 넣으면, 문자열이 넣은 문자 중 하나와 일치하면 매칭이 이뤄짐. 즉 OR 개념이라고 할 수 있음.
캐릿 (caret) ^ 문자가 여는 대괄호 바로 뒤에 있으면 문자가 반전됨.
CODE
matchObj = re.search('Why [a-z]o serious\?', 'Why so serious?')
print(matchObj)
matchObj = re.search('Why [^0-9]o serious\?', 'Why so serious?')
print(matchObj)
OUTPUT
<_sre.SRE_Match object; span=(0, 15), match='Why so serious?'>
<_sre.SRE_Match object; span=(0, 15), match='Why so serious?'>- [a-z] 는 영문 소문자 하나 ('s')와 일치되므로, 매칭 결과 반환됨.
- [^0-9] 는 숫자를 제외한 문자 하나에 일치되므로, 's'는 숫자가 아니기에 매칭됨.
문자 집합: \w \W, \d \D, \s \S, \b \B
| \w | 단어 문자 1개와 일치 단어 문자: 영문 대소문자, 숫자 0-9, 언더바'_' |
| \W | 단어 문자 이외의 문자 1개 일치 즉, 공백 문자, 특수 문자 |
| \d | 숫자 문자 1개에 일치 |
| \D | 비숫자 문자 1개에 일치 |
| \s | 공백 문자 1개에 일치 공백 문자: 빈칸, 탭('\t'), 개행('/n') |
| \S | 공백 문자 이외의 모든 문자 1개에 일치 |
| \b | 단어 경계 1. 첫 문자가 단어 문자인 경우, 첫 문자 앞에서 2. 인접한 두 문자 중 하나만 단어 문자인 경우, 그 사이에서 3. 끝 문자가 단어 문자인 경우, 끝 문자 뒤에서 |
| \B | 비단어 경계 1. 첫 문자가 비 단어 문자인 경우, 첫 문자 앞에서 2. 두 단어 문자 사이 도는 두 비 단어 문자 사이에서 3. 끝 문자가 비 단어 문자인 경우, 끝 문자 뒤에서 4. 빈 문자열에서 |
OR, 반복
| : 다자택일
단어 'one', 'two','three' 중 하나에 대응하고 싶다면 | 를 쓰면 됨.
|로 나열한 단어들의 순서가 중요한 순간
matchObj = re.findall('one|oneself|onerous', 'oneself is the one thing.') print(matchObj)
OUTPUT
['one', 'one']- ‘oneself’가 있음에도 oneself에 일치되지 않음.
- 정규식은 overlapping된 부분을 또 찾지 않기 때문에, ‘one’을 찾고 나서 남은 문자열은 ‘self is the one thing.’
해결 방법
- 더 긴 oneself를 one 앞에다 두기.
- 단어 경계: \bone\b|\boneself\b